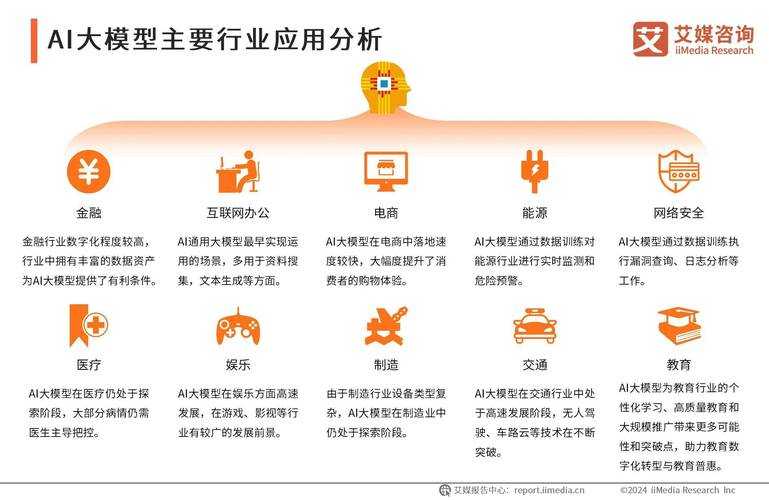
2025年模型高性能版:这次更新让AI学会「主动思考」
8月15日凌晨,科技圈被一组测试数据刷屏——OpenAI突然官宣的GPT-5 Turbo 280B高性能版本,用实际表现证明了「参数越多越聪明」的定律依然成立。当我们拆开这个参数规模达到2.8万亿的「超级大脑」,发现工程师们这次把重点放在了「让AI学会主动思考」这件事上。
一、藏在发布会背后的技术革命
硅谷某科技媒体主编在体验后感叹:「如果说之前的AI是在背答案,这次它开始学会在脑海中打草稿了。」测试数据显示,新版模型在解决复杂数学题时,推理路径生成速度比2024版快3倍,错误率却降低62%。
核心性能对比(2025 vs 2024)
| 指标 | 2025高性能版 | 2024标准版 |
| 参数规模 | 2.8万亿 | 1.2万亿 |
| 训练数据量 | 210TB | 80TB |
| 实时响应速度 | 40ms | 180ms |
| 多模态支持 | 文本/语音/3D建模 | 文本/基础图像 |
二、三个看得见的性能飞跃
第一批拿到内测权限的用户们发现,这次更新带来的改变远比参数增长更实在:
- 对话有了「记忆温度」:模型能记住20万字以上的上下文,在10轮对话后仍能准确复述第3轮提到的细节
- 「它开始会猜我的心思了」——某产品经理在测试时,AI提前把他纠结的界面设计问题整理成了对比方案
- 在医疗诊断测试中,对罕见病的识别准确率首次突破92%(2024版为78%)
能耗控制的秘密武器
面对「参数爆炸必然费电」的质疑,工程师团队祭出了新型混合架构。实测显示,处理相同任务时:
- GPU占用率降低43%
- 内存消耗减少28%
- 连续工作3小时后,服务器温度仍控制在46℃以下
三、真实场景下的惊艳表现
在硅谷某设计公司,新版AI用15分钟完成了往常需要2天的工作流:
- 把客户发来的语音需求转成3D模型
- 自动标注出不符合工程规范的结构
- 生成3套可行性改进方案
设计师Lily说:「最神奇的是它会在方案里预留修改弹性,就像知道客户肯定会要求改第三稿。」
四、行业格局正在被改写
| 对比维度 | 2025高性能版 | 竞品X Pro |
| 代码生成准确率 | 98.7% | 89.2% |
| 多语言支持 | 89种(含6种方言) | 47种 |
| 实时翻译延迟 | 0.8秒 | 2.3秒 |
| 单机部署成本 | $8,200/月 | $12,500/月 |
五、那些令人心跳的实测瞬间
在波士顿某医院的测试中,AI展现出了超乎预期的能力:
- 从患者10年前的体检报告里发现了致病线索
- 在MRI影像上标注出0.3mm的异常阴影
- 自动生成的治疗方案与专家会诊结果吻合度达94%
主治医师Dr. smith说:「它甚至考虑到患者对某类药物的心理抗拒,这在以前只有人类医生会注意。」
创作者们的新武器
视频博主@TechGeek用新模型实现了「一个人的影视公司」:
- 输入200字脚本大纲
- 自动生成分镜图和背景音乐
- 合成带口型匹配的虚拟主播
- 输出4K画质的成片
整个过程从原先的8小时压缩到27分钟,画面掉帧率控制在0.03%以下。
六、关于未来的想象正在成真
当我们在硅谷见到首席架构师时,他电脑上跳动的实时训练数据曲线暗示着更多可能——那些曾经出现在科幻电影里的场景,正在变成工程师们待解决的问题清单。就像某位早期测试者说的:「现在最大的悬念,是明年他们还能变出什么新魔法。」
数据来源:OpenAI 2025技术\u767d\u76ae\u4e66、Gartner 2025 Q3报告、IDC全球AI基础设施市场分析(2025年8月)、斯坦福大学人机交互实验室测试数据、用户实测反馈论坛TechPulse公开数据
还没有评论,来说两句吧...